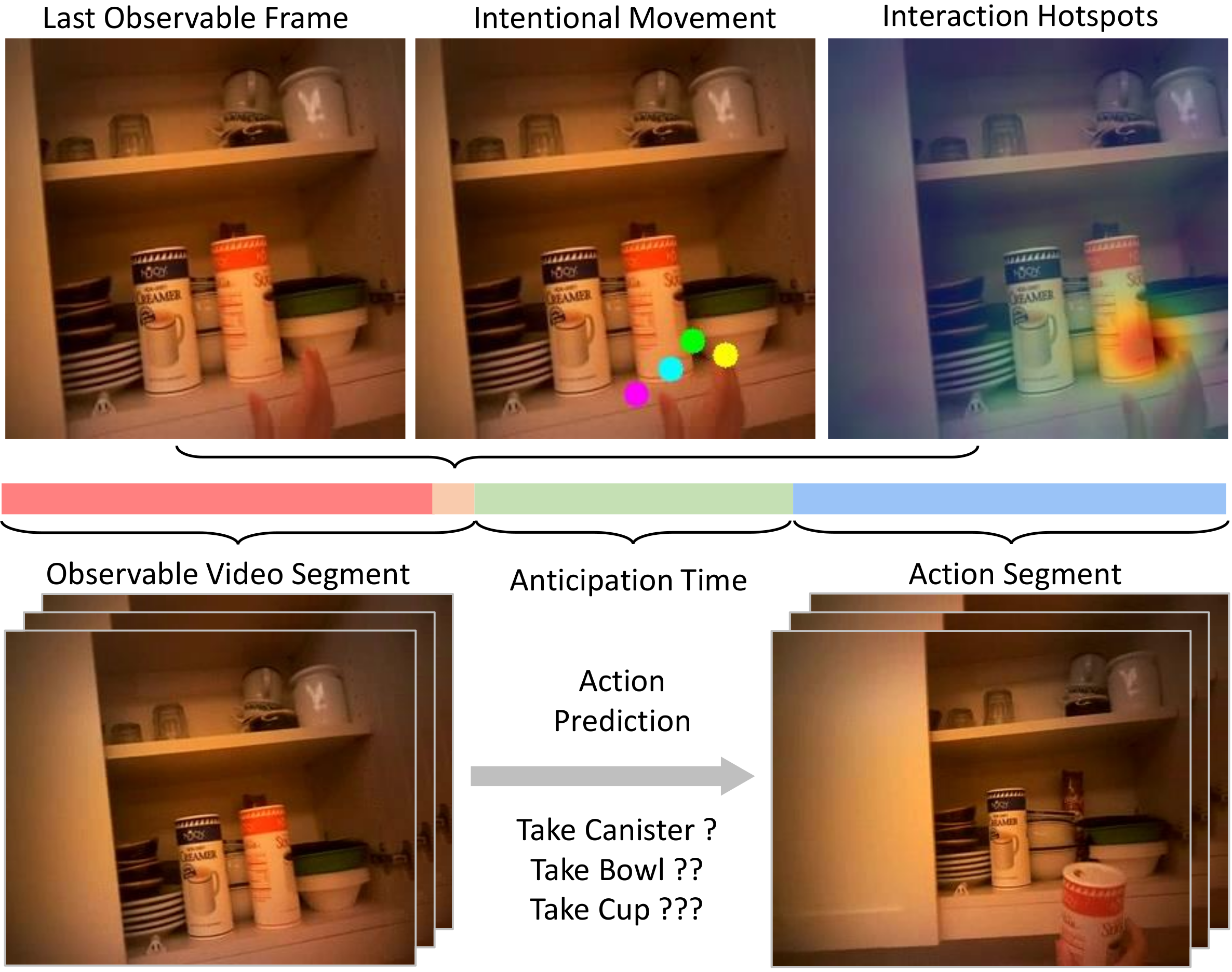
In addition to future action label, our model also predicts the interaction hotspots on the last observable frame and hand trajectory (in the order of yellow, green, cyan, and magenta) from the last observable time step to action starting point. Visualizations of hand trajectory are forecasted to the last observable frame. (Best viewed in color)
Abstract
We address the challenging task of anticipating human-object interaction in first person videos. Most existing methods ignore how the camera wearer interacts with the objects, or simply consider body motion as a separate modality. In contrast, we observe that the international hand movement reveals critical information about the future activity. Motivated by this, we adopt intentional hand movement as a future representation and propose a novel deep network that jointly models and predicts the egocentric hand motion, interaction hotspots and future action. Specifically, we consider the future hand motion as the motor attention, and model this attention using latent variables in our deep model. The predicted motor attention is further used to characterise the discriminative spatial-temporal visual features for predicting actions and interaction hotspots. We present extensive experiments demonstrating the benefit of the proposed joint model. Importantly, our model produces new state-of-the-art results for action anticipation on both EGTEA Gaze+ and the EPIC-Kitchens datasets.
Demo Video
Cite
If you find this work useful in your own research, please consider citing:
@inproceedings{liu2019forecasting,
title={Forecasting human object interaction: Joint prediction of motor attention and actions in First Person Video},
author={Liu, Miao and Tang, Siyu and Li, Yin and Rehg, James},
booktitle={ECCV},
year={2020}
}
Contact
For questions about paper, please contact mliu328 at gatech dot edu